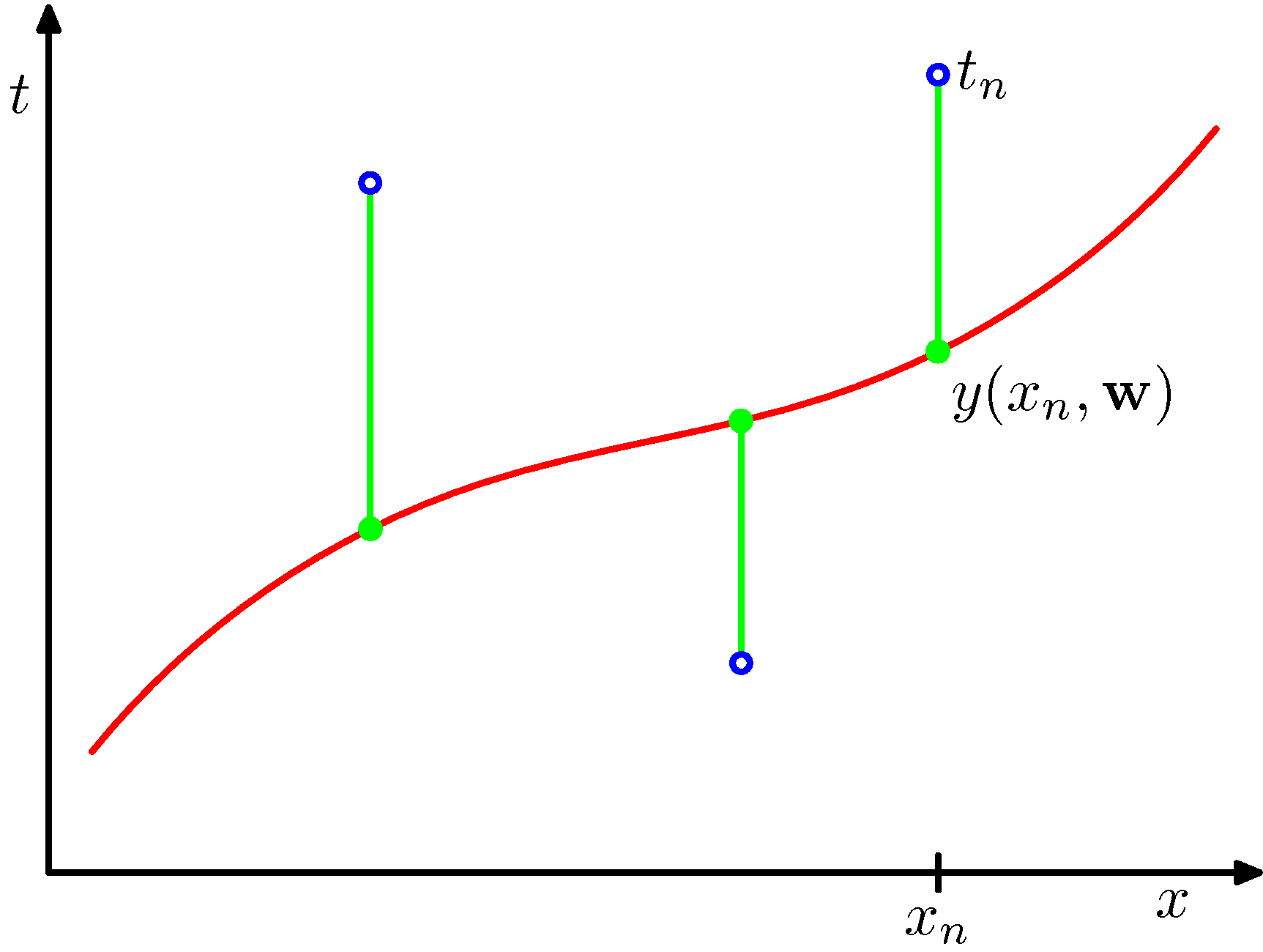
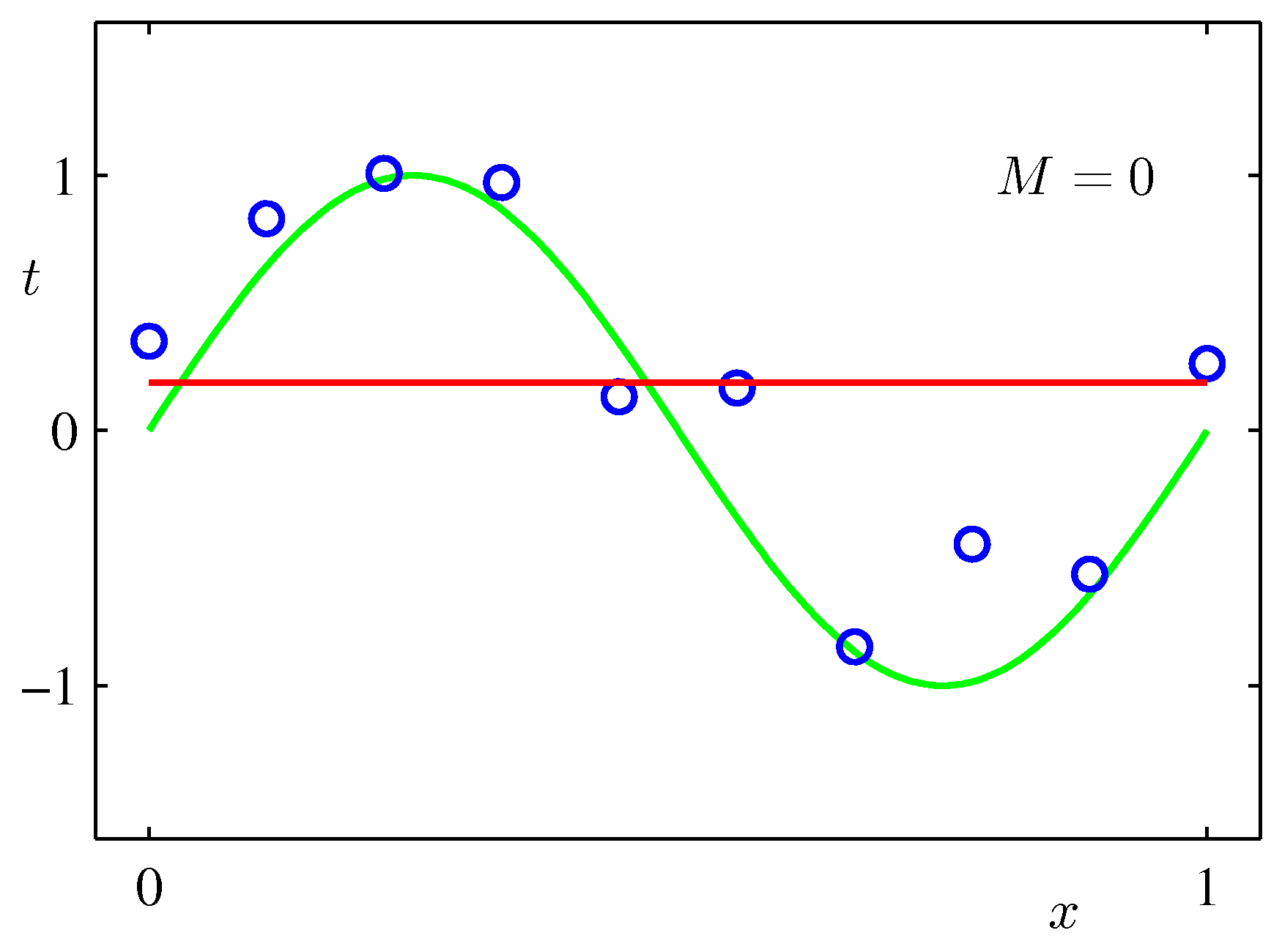
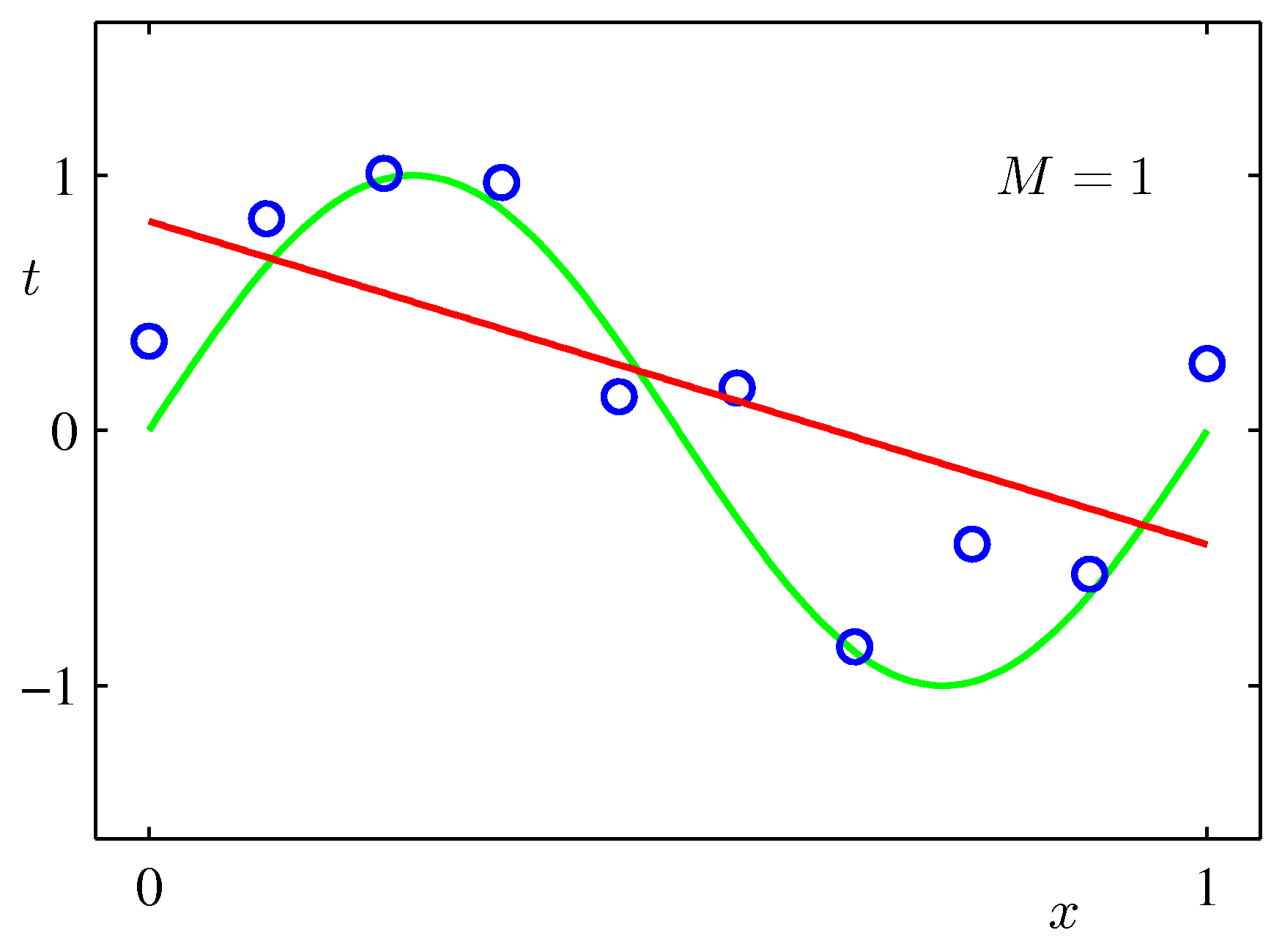
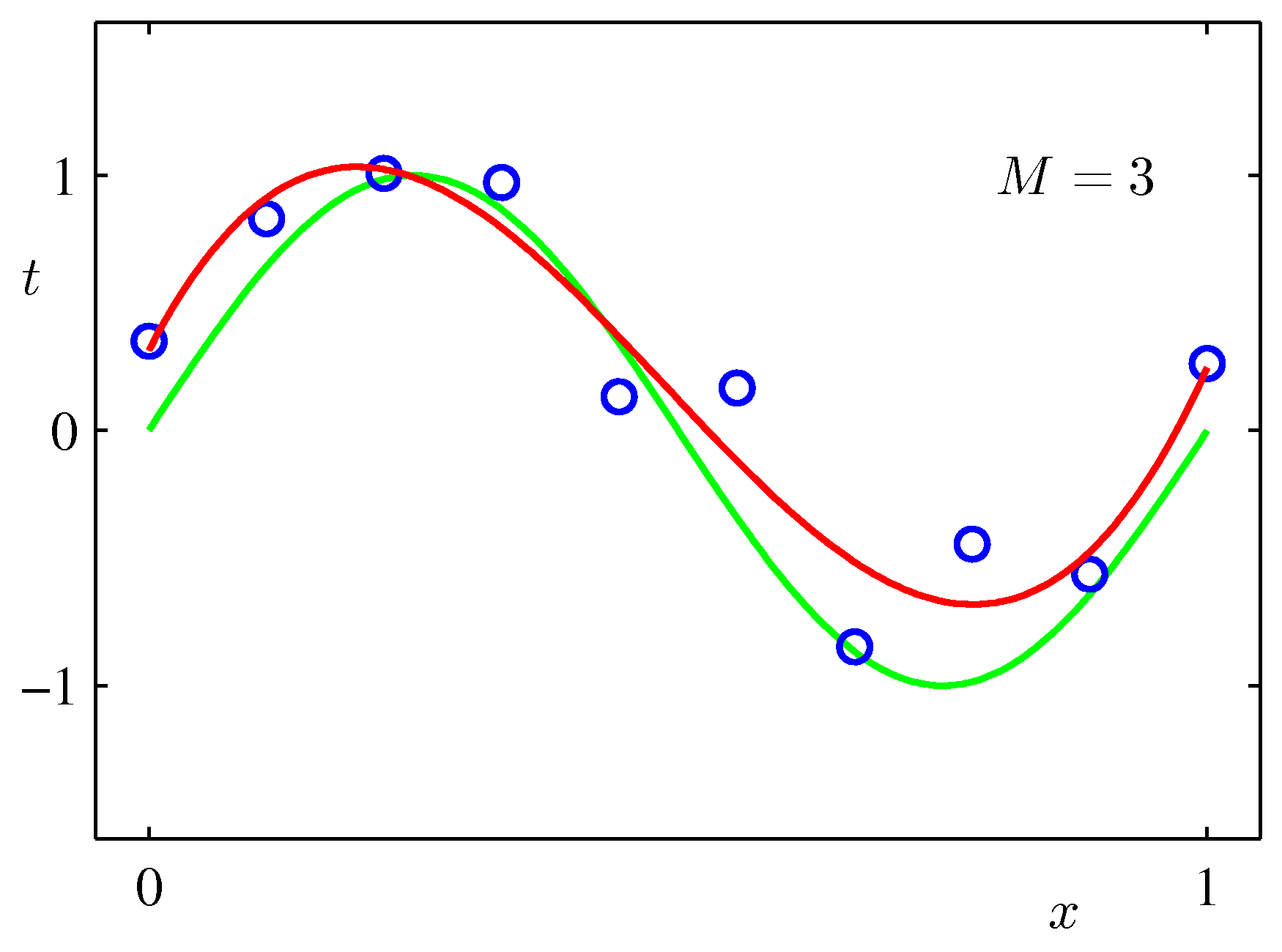
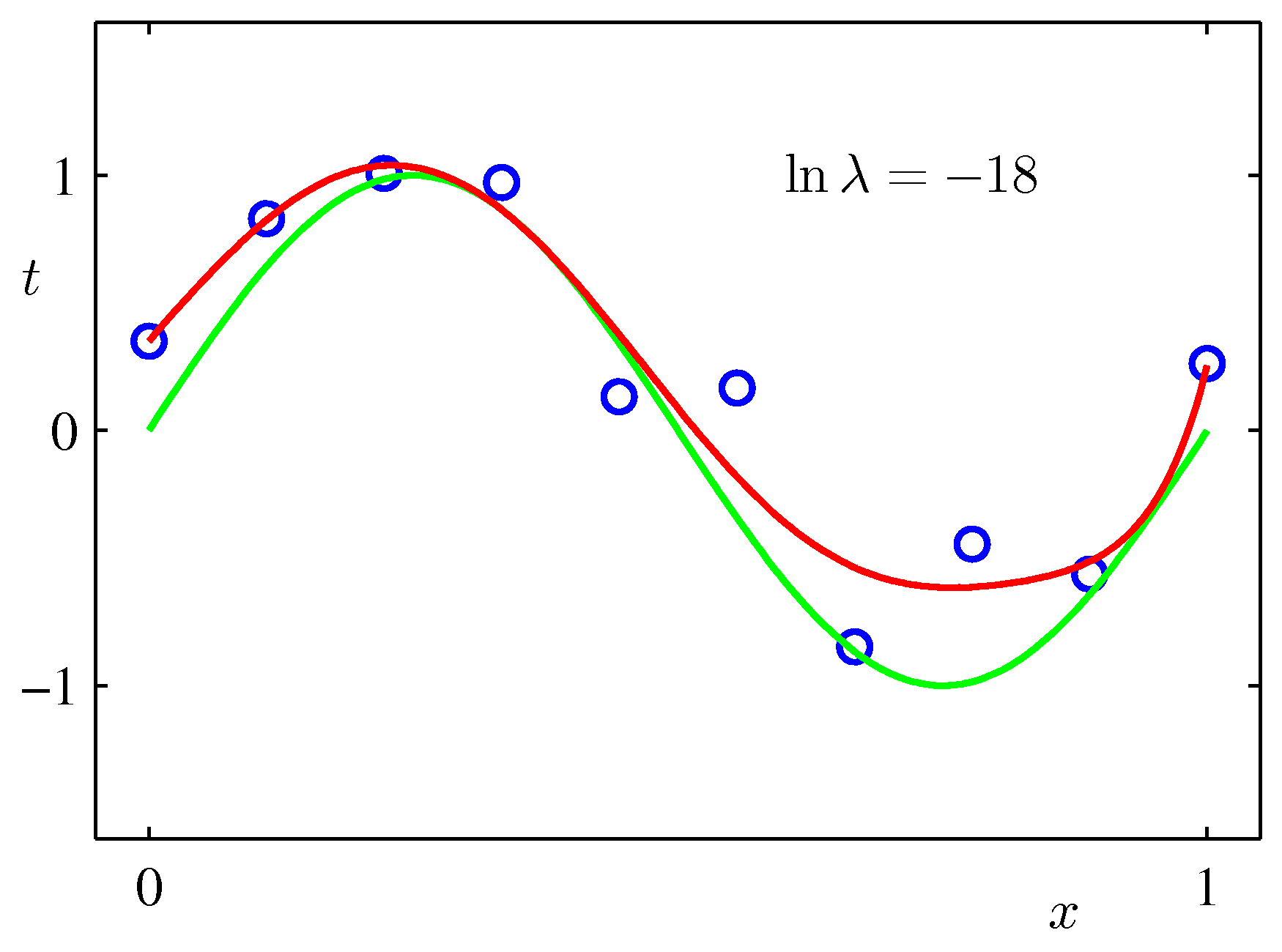
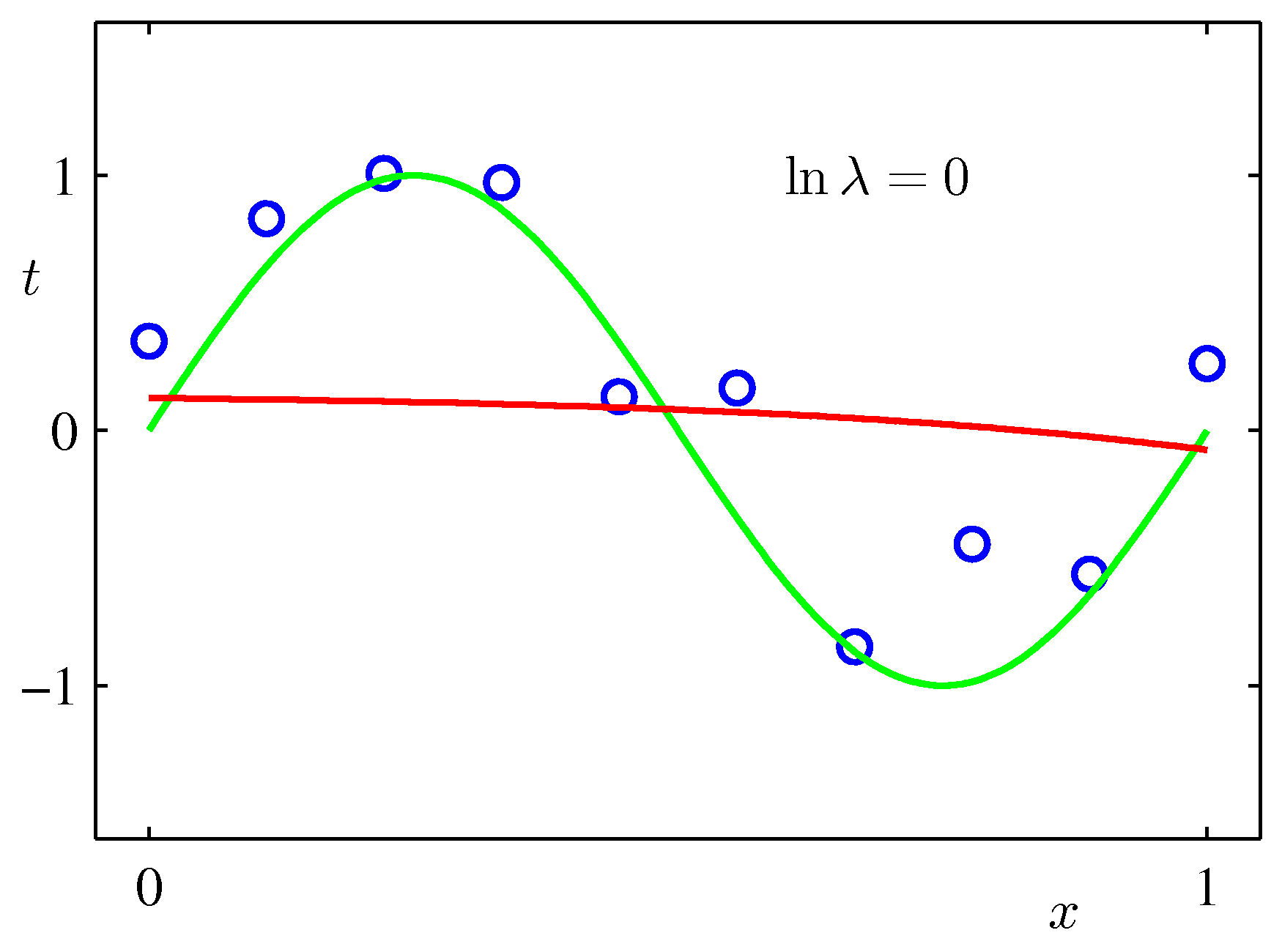
フィッティング関数の次数=2
切片= 0.4164497190283239
0.01799 -0.22651 0.00000
alpha=0.05, deg=2, R2=0.07319032622357546
フィッティング関数の次数=5
切片= 1.4212147654535712
0.06024 -0.68241 2.41715 -2.35013 -1.39076 0.00000
alpha=0.05, deg=5, R2=0.9246990582148639
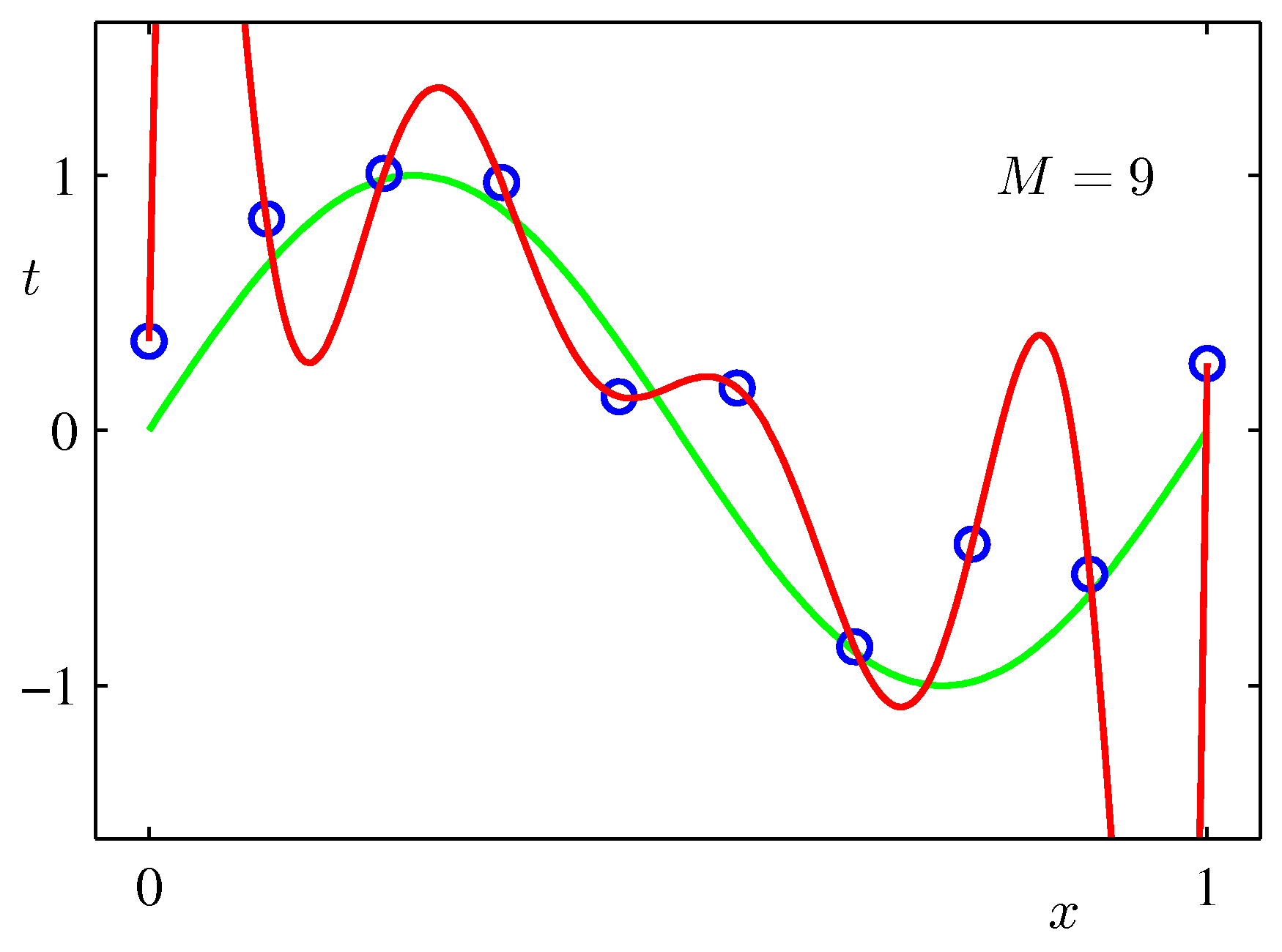
フィッティング関数の次数=10
切片= 1.1774753605356092
0.00004 -0.00187 0.02135 -0.09331 0.13959 0.01035 0.04015 -0.05689 -0.53787 -0.93996 0.00000
alpha=0.05, deg=10, R2=0.9279894262666633
フィッティング関数の次数=2
切片= 0.41324330712538765
0.01733 -0.22297 0.00000
alpha=0.1, deg=2, R2=0.07365235557690586
フィッティング関数の次数=5
切片= 1.3956163105706856
0.05194 -0.58207 2.00201 -1.68759 -1.68644 0.00000
alpha=0.1, deg=5, R2=0.9099839189650605
フィッティング関数の次数=10
切片= 1.1369338135777762
0.00005 -0.00203 0.02172 -0.08865 0.10783 0.07840 0.02311 -0.15134 -0.52052 -0.82604 0.00000
alpha=0.1, deg=10, R2=0.9273969899665108
フィッティング関数の次数=2
切片= 0.4013772751146817
0.01488 -0.20985 0.00000
alpha=0.3, deg=2, R2=0.075297455097181
フィッティング関数の次数=5
切片= 1.1803628262120314
0.03785 -0.42233 1.41528 -0.99638 -1.61719 0.00000
alpha=0.3, deg=5, R2=0.8613623948014627
フィッティング関数の次数=10
切片= 1.045376268038547
0.00010 -0.00297 0.02865 -0.11117 0.12832 0.12332 -0.03555 -0.24795 -0.47652 -0.62312 0.00000
alpha=0.3, deg=10, R2=0.9219499395256724
フィッティング関数の次数=2
切片= 0.39085105183565494
0.01271 -0.19822 0.00000
alpha=0.5, deg=2, R2=0.07667142623387724
フィッティング関数の次数=5
切片= 1.0120046107744969
0.03038 -0.34092 1.14105 -0.76578 -1.40090 0.00000
alpha=0.5, deg=5, R2=0.8090359941215963
フィッティング関数の次数=10
切片= 0.9911163642329129
0.00010 -0.00308 0.03004 -0.11841 0.14266 0.12584 -0.06313 -0.27105 -0.44588 -0.53172 0.00000
alpha=0.5, deg=10, R2=0.9158860358061822
フィッティング関数の次数=2
切片= 0.369088997747132
0.00823 -0.17418 0.00000
alpha=1.0, deg=2, R2=0.07925710154300392
フィッティング関数の次数=5
切片= 0.7548628842693
0.02008 -0.23028 0.77993 -0.50957 -1.02103 0.00000
alpha=1.0, deg=5, R2=0.6971672203411846
フィッティング関数の次数=10
切片= 0.9027236043260879
0.00006 -0.00236 0.02623 -0.11204 0.14863 0.11277 -0.08989 -0.27591 -0.39200 -0.41894 0.00000
alpha=1.0, deg=10, R2=0.9008057664473685
フィッティング関数の次数=2
切片= 0.3384880212715846
0.00195 -0.14044 0.00000
alpha=2.0, deg=2, R2=0.08230979030066121
フィッティング関数の次数=5
切片= 0.5210910480469141
0.01125 -0.13596 0.47710 -0.31679 -0.65662 0.00000
alpha=2.0, deg=5, R2=0.5614928171903719
フィッティング関数の次数=10
切片= 0.7943102700898788
-0.00005 -0.00053 0.01501 -0.08398 0.13406 0.08279 -0.10212 -0.25133 -0.32304 -0.31727 0.00000
alpha=2.0, deg=10, R2=0.8728212655743505